Large Language Models, voortgetrokken door ChatGPT, hebben de afgelopen jaren een snelle opmars gemaakt. Maar de resultaten die je met een dergelijk AI-model boekt zijn afhankelijk van je prompt. Ben je beter in prompten? Dan geeft ChatGPT jou betere resultaten.
Wat is prompt engineering?
Prompt engineering is een (wetenschappelijke) discipline die zich bezighoudt met het maken en verfijnen van prompts. Door betere prompts te gebruiken kunnen betere antwoorden worden gegenereerd met Large Language Models zoals ChatGPT.
Anatomie van een prompt
Een prompt kan uit een aantal onderdelen bestaan. In de basis maken we onderscheid tussen:
- De instructie: hierin vertel je het model wat je wilt dat het doet. Bijvoorbeeld een titel genereren voor een blog (instructie). Je kunt ook een vraag stellen. Inde instructie kunnen we nog een aantal zaken toevoegen:
- Voorbeelden: het geven van voorbeelden kan ervoor zorgen dat een LLM beter weet wat je bedoelt, met als resultaat dat het model betere content genereert.
- Cues: je kunt ook een “starter” meegeven. Wanneer je ChatGPT vraagt om te schrijven over de attracties van Parijs. Dan kan een cue zijn: “De top attracties in Parijs zijn…”. De LLM zal een cue aanvullen.
- Templates: je kunt ChatGPT vragen om te antwoorden in een specifieke template. Wanneer je ChatGPT vraagt om een overzicht te maken van ski resorts in Europa. Bijvoorbeeld: geef de skigebieden terug in het volgende formaat: naam | land | pistekilometers
- De context: voor sommige prompts kun je ook context toevoegen. Als je bijvoorbeeld aan ChatGPT vraagt om een email samen te vatten zul je deze moeten meesturen. Het wordt aangeraden om de instructie van de context te scheiden. Dat kan bijvoorbeeld door een regel leeg te laten.
Waar moet een goede prompt aan voldoen?
OpenAI (het bedrijf achter ChatGPT) geeft zelf een aantal tips voor wie goede prompts wilt maken.
- Gebruik altijd het laatste model. Logisch, want deze presteren over het algemeen beter. Wanneer je in een specifieke branche werkt (bijvoorbeeld de zorg) kan het zijn dat er voor die branche specifieke modellen bestaan die beter presteren omdat ze enkel op data uit de zorg zijn getraind.
- Maak onderscheid tussen de instructie en de context. Deze bespraken we zojuist al. OpenAI geeft aan dat je deze twee kunt splitsen door er ### of “”” (drie dubbele aanhalingstekens) tussen te zetten.
- Ben zo duidelijk mogelijk over wat je wilt genereren, waar je het voor gebruikt, en ook over de lengte, stijl en het formaat.
- Dus niet: “schrijf een gedicht over de liefde” maar “Schrijf een gedicht van vier alinea’s over de liefde tussen een Franse kunstenaar en zijn muze. Focus op het verlies van de muze.”
- Gebruik voorbeelden. Als het zonder of met maar een voorbeeld niet werkt, gebruik dan meerdere voorbeelden.
- Vermijd onduidelijke instructies: Niet “schrijf een alinea over”… maar: “schrijf een alinea van 3 tot 5 zinnen over”
- Zeg wat het model wel moet doen, in plaats van wat niet te doen.
Parameters
Met parameters kun je een aantal zaken instellen in ChatGPT. Zo kun je met de temperatuur instellen hoe “creatief” het model moet zijn. De temperatuur instellen op “2” maakt het model erg creatief (mijn ervaring is meestal te creatief). Een temperatuur van “0” maakt het model heel deterministisch (betekent als je dezelfde vraag stelt, krijg je steeds hetzelfde antwoord). In sommige situaties wil je dat het model deterministisch is (bijvoorbeeld samenvatten of waardes uit een tekst halen). In andere situaties (bijvoorbeeld genereren van oplossingen of marketing-content) wil je dat het model deterministisch is.
Je kunt de temperatuur niet altijd instellen. In de ChatGPT playground kan dit wel (zie afbeelding).
Let op, hiervoor moet je wel geld op je account hebben staan (je hoeft geen maandelijks abonnement te hebben). Een paar euro is al genoeg.
Er zijn nog een aantal andere parameters die je kunt instellen, maar de temperatuur is wel de belangrijkste.
Leer het model vissen, of geef het model een vis
Oké, dit klinkt misschien cryptisch. Maar de basis is simpel. Modellen zoals ChatGPT hallucineren nog weleens wanneer je ze open vragen stelt en het model zijn “eigen” kennis gebruikt. Maar je kunt het model dus ook vragen om data uit een grotere tekst te halen, bijvoorbeeld een e-mail.
Geef het model een vis
Deze methodologie wordt in Brex’s Prompt Engineering Guide aangehaald. Je gebruikt het wanneer je vragen stelt over content die je zelf mee geeft. Bijvoorbeeld op de volgende manier:
Je krijgt zo meteen een email te zien. Ik wil dat je daar het factuurnummer en het klantnummer uithaalt. Je geeft ze terug in JSON formaat, op de volgende manier: {"factuurnummer":"12345","klantnummer":"12345"}
###
Beste, ik zou graag nogmaals factuur 23433 willen ontvangen voor klant: A1234.
Bij voorbaat dank!Leer het model om zelf te vissen
Een andere manier om ChatGPT betrouwbare informatie te laten gebruiken is door het model zelf informatie te laten opzoeken. Dat kan bijvoorbeeld met embeddings, function calling of het gebruik van API’s. In dat geval kan ChatGPT bijvoorbeeld informatie opzoeken in een database. In dit artikel wil ik hier niet te diep op ingaan, omdat het vrij complex is. Maar het kan dus wel. Dit is ook waar Retrieval Augmented Generation (RAG) aan bod komt.
Zero-shot, one-shot of multi-shot prompting
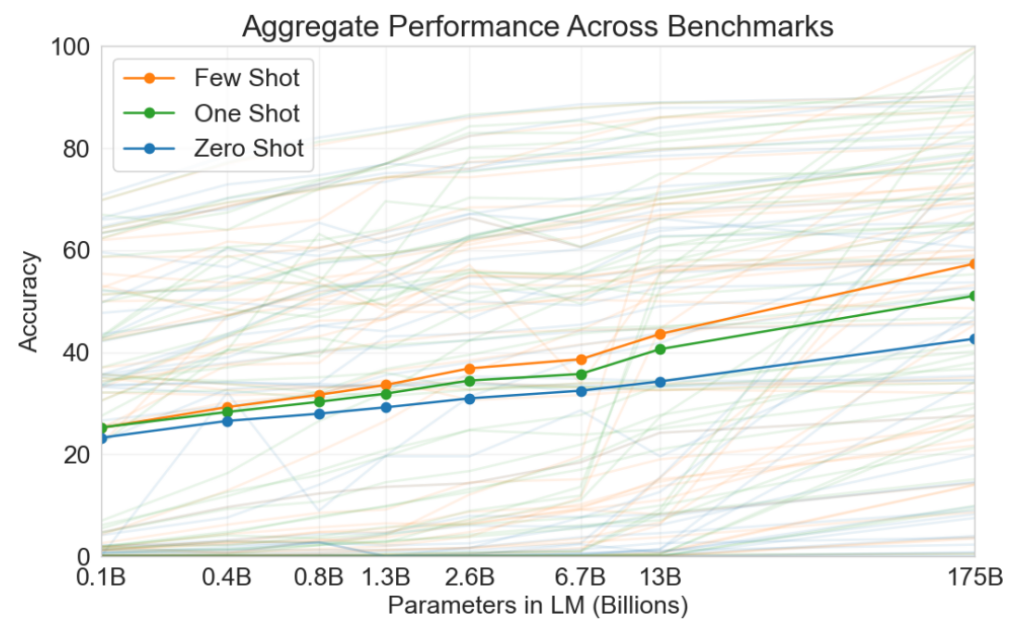
Het gebruik van voorbeelden zorgt ervoor dat de meeste GPT’s betere content genereren, zoals aangetoond in dit paper. Dit geldt in het bijzonder voor talen die relatief gezien minder gebruikt worden (zoals Nederlands bijvoorbeeld).
Chain of thought (CoT)
Chain of thought prompting is een waardevolle methode voor wie LLM’s wilt laten redeneren. Vooral “Cito-toets” achtige vragen doen het erg goed bij chain-of-thought. Kijk maar eens naar onderstaand voorbeeld:
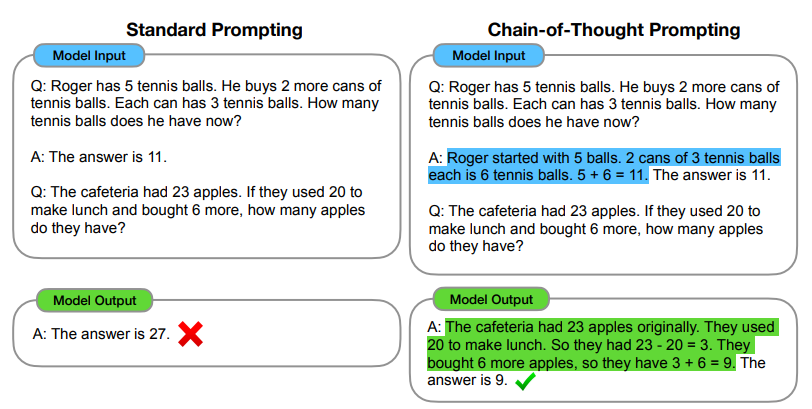
Meer weten over chain-of-thought? Het concept wordt uitgelegd in dit artikel.
Tree of Thoughts (ToT)
Wetenschappers blijven steeds nieuwe methodes ontwikkelen om LLM’s correcte output the laten genereren. Een andere manier van prompten die recent populair is geworden is Tree of Thoughts.
Het concept is simpel. We delen een vraagstuk op in meerdere stappen. We laten steeds drie experts een oplossing bedenken voor een stap. Na elke stap besluiten de drie experts welke oplossing doorgaat naar de “volgende ronde”.
Je gaat onderstaand probleem oplossen met Tree of Thought (ToT).
- Stel je voor dat er drie experts zijn
- Elke expert stelt steeds een stap voor om het probleem oAp te lossen
- Na elke ronde evalueren alle experts alle drie de ideeën
- Het beste idee wordt uitgekozen en gaat door naar de volgende ronde
Het probleem: je hebt twee planken van elk twee meter. Je hebt ook een emmer. Met de planken en de emmer moet je een snel stromend riviertje oversteken van 3 meter.De prompt levert een lange response op. Probeer het zelf maar eens uit! In mijn geval stelde een van de experts bijvoorbeeld voor om de emmer te vullen met stenen. Slim, daar had ik zelf nog niet aan gedacht!
Wil je meer leren over prompt engineering? Overweeg dan om mijn prompt engineering training te boeken!